18 minute read
SCALING AI WITHIN OPEN BANKING: BUILDING TRUSTLY’S MACHINE LEARNING PLATFORM


If data is the new oil that fuels long-term profitability, North American open banking is a reservoir yet to be discovered, buried deep down within decades of financial system inefficiencies and complexities. Open banking data is both rich and diverse. A lot can be learned by looking at someone’s bank activity data. By knowing someone’s income or how they spend their money, one can draw behaviour models for several purposes. From fighting financial crime and fraud to providing relevant recommendations, open banking data remains one of the most relevant promises towards the democratisation of financial services with machine learning (ML). When it comes down to ML, data is king. The higher the relevance and quality of the data available for your ML models, the better they will perform. ‘It is all about the data!’ This line stuck with me as I decided to join Trustly as their first machine learning engineer in early 2023. It’s impressive what we have accomplished in such a short timeframe since we started building our in-house machine learning platform.
Data-driven decisions can be a major differentiator in the competitive financial landscape and, ultimately, offer a cutting-edge experience for your customers – if the data is good enough. Trustly has built a comprehensive open banking platform that challenges siloed bank data. By connecting the data from more than 99% of financial institutions in North America, Trustly is pioneering the next generation of intelligent financial services.
If data is gold, machine learning is how we mint and make it shine. Open banking data offers several challenges for machine learning applications, requiring strong security guarantees as it handles sensitive and personal identifiable information (PII). Given privacy constraints, such data is subject to strict regulations in terms of when you can consult and for what purposes. Often, you will be granted access for a limited period of time during the customer interaction. As a result, machine learning systems using open banking data usually operate online or near-real time and, thus, deal with all the complexities and challenges that come along. Smart safety guardrails are paramount as the connection with third-party financial institutions can unexpectedly fail or take too long to respond. US financial institutions have diverse service levels. Not all US banks have direct APIs ensuring the most up-to-date data. As a result, our ML models must be robust enough to rely on outdated data or have a reliable fallback strategy in place.
The lack of open banking standardisation presents another big challenge for ML applications. Each financial institution provides information in their own format, while others don’t provide it at all. There is no widely adopted standard for bank activity expense categorisation. One financial institution can tag a transaction made in a pub as ‘Entertainment’ while another as ‘Food & Beverage’. The lack of standards makes it difficult to train models with data across different financial institutions.
At Trustly, we designed and implemented an inhouse machine learning platform to deal with the inherent challenges of open banking by developing a unified standard feature store, so that we could develop models that benefit from data across different financial institutions. We introduced model governance and several pre- and post-deployment safeguards to de-risk online near real-time machine learning systems. We also decreased model response time from seconds to just a few milliseconds. Today, we’re a major player in machine learning and AI in the open banking space and we’re well-positioned to continue leading the pack.
REAL-TIME GUARANTEED PAYMENTS DEPEND ON OPEN BANKING RISK MODELS
In the US, traditional payment rails like ACH take days to process, and it’s been cumbersome and inconvenient for customers to pay with their bank due to poor user experience and long settlement times. Can you imagine purchasing crypto assets and receiving them days later? Through our machine learning platform coupled with open banking data, we made guaranteed payments on the ACH rail available in real time.
Now, you can log into your bank, choose from which bank account you want to pay, and with a few clicks, your payment is complete. The merchant receives their payment, and you receive your digital assets immediately . That’s an entirely different experience from the archaic ACH payment without open banking.
Any customer can pay straight from their account, from any bank, with the click of a button and without needing a credit card or manually inputting account and routing numbers. Additionally, Trustly’s open banking platform helps merchants reduce expensive processing fees (the average credit card processing fee is 2.24%, which adds up to merchants’ payment costs).
Guaranteed Payments Reduce Risk for Merchants
To make the ACH payment happen in real-time, Trustly assumes the risk and pays the merchant directly at the time of the transaction and then later collects the payment from the customer’s account. The risk: Trustly may be unable to collect the payment due to fraud (which is still much lower than card-not-present fraud, thanks to the bank’s multi-factor authentication) or simply because the customer didn’t have sufficient funds during the transaction. That’s where machine learning comes in. ML bolsters the Trustly risk engine to mitigate against risky transactions and ensure we can still provide cost-effective guaranteed payments.
One of the most common ACH return codes is R01: Insufficient Funds. Trustly’s payment product guarantees the transaction instantly, at the moment of the purchase, but will only settle the transaction, i.e. collect the funds from the customer’s account, later after the ACH process has been completed. Even if the customer has funds in their account at the time of purchase, the risk of insufficient funds persists since ACH processing can take up to three days. The customer might spend those available funds elsewhere, causing the transaction to fail.
Why Bank Connectors Matter
Trustly built payment connectors with most banks in North America, covering 99% of financial institutions between Canada and the US. It’s no small feat, especially considering that other open banking providers use screen scraping, which is less reliable and less secure than doing the work to build bank connections from the beginning.
One of the major benefits of proprietary bank connections? We built them, and we maintain them. It’s a big reason our data is so reliable. Trustly needs accurate, bank-grade data that’s so reliable it can power guaranteed payments.
This technology allows Trustly to access and use fresh open banking data to conduct risk analysis and decide whether to approve or decline a transaction. Our platform’s capability is directly tied to the success of our risk models. While the stakes are high, the ability to access fresh consumer financial data gives us a competitive advantage to build data products at scale using machine learning. We’re the only open banking provider using this approach.
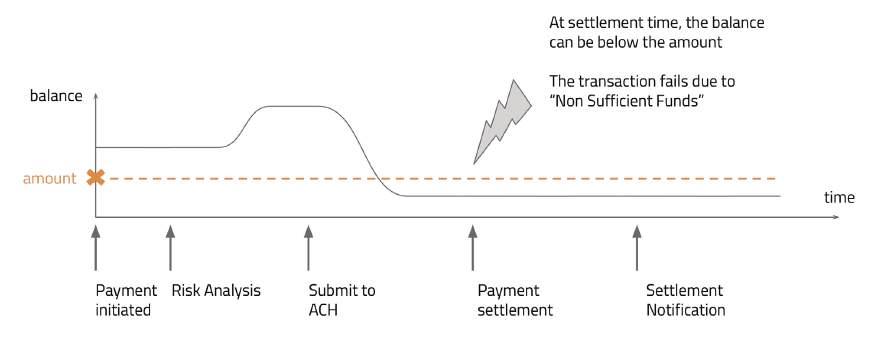
Toy example depicting the ‘non-sufficient funds’ risk scenario where the ACH transaction fails, causing financial loss
Consider the risk evaluation scenario depicted in Figure 1.
1. When the payment is initiated, the customer authenticates to their financial institution and allows Trustly to retrieve their account information through open banking technology. Only when the customer initiates the payment, are we able to retrieve balances, transaction history, debts, etc.
2. Next, we perform the risk analysis and decide to approve or decline the payment. We check the customer’s account balance to ensure they have the balance to cover the transaction amount. Note that there is a delay between the risk analysis and the transaction settlement, thus, despite the customer’s balance being enough when the payment is initiated, there is no guarantee that it will remain greater than the transaction amount when the payment is settled. In fact, the customer balance can vary if they receive payouts, transfer money or other pending transactions are settled. This uncertainty whether the balance will still cover the amount during settlement is the ‘non-sufficient funds’ risk we discussed. chart depicting an example of risk analysis representing the processing times of each step involved, from calling external data providers to the model inference and associated decision policy
3. After Trustly has submitted the payment, ACH will process and try to settle it. If the customer’s balance is not enough to cover the transaction amount value, the transaction fails and Trustly incurs a loss, as it has already guaranteed the payment to the merchant. Up to three business days after the ACH submission, Trustly is notified if the transaction has completed successfully or failed.
As you can see, powerful machine learning models are needed to identify risky transactions and minimise company losses.

Trustly machine learning risk evaluation has to operate with strict time constraints and be robust enough to cope with potential failures and data inaccuracies from external data providers. Consider the Gantt chart depicting the near-real time machine learning risk inference in Figure 2. Once the risk analysis starts, we retrieve open banking data from the customer’s financial institution and enrich it with API calls to external providers, including our own internal data. External providers, such as the financial institution itself, are prone to incidents causing data disruption, which can degrade the data quality from third parties. However, the risk analysis is robust enough to tolerate potential data lapses. The data sources go through our inhouse processing pipeline to produce rich engineered features. Not all processes are dependent on each other, so they can run in parallel. By processing independent parts of the risk analysis asynchronously, we can drastically reduce the total time. Of course, some steps are dependent, for example, the model requires all its features to be computed before starting the inference. Once we have produced the risk scores, we apply a threshold decision considering the amount and the risk of the transaction not having sufficient funds among other business rules and controls. In simple terms, we balance the trade off between approving more transactions while minimising risk.
Machine Learning Platform: High Stake Decision-Making at Scale
task that takes the longest to run (as opposed to summing up the time of individual tasks). Typically, the model inference time becomes the bottleneck after we employ async processing as it is a slow task and highly dependent on others. Feature selection and regularisation means the process of making the models lighter and leaner. For example, the fewer features a model uses, the fewer tasks it depends on and the less time it will take in inference. We applied a backwards feature selection technique to prune the models as much as we can without significant predictive performance loss. Backwards feature selection consists of repeatedly training and evaluating models, reducing the number of features at each iteration until the performance deteriorates. For example, if we have 500 features available we train a model with all features and evaluate its performance. Then, we remove features based on some criteria, like the less relevant features in terms of importance or information value for the original model. We retrain and evaluate the model without the removed features. We repeat the process until we observe a drop in performance when compared to the original model.
Trustly connects businesses to thousands of financial institutions in the US and Canada as an account-toaccount payment method with industry-leading low latency even during peak transaction processing times.
We built our machine learning platform to support our risk analysis for Trustly Pay Guaranteed Payments. And when it comes to scale, Trustly connects businesses to thousands of financial institutions in the US and Canada as an account-to-account payment method with industry-leading low latency even during peak transaction processing times.
Our most requested models operate and maintain robust request per second (RPS) performance under regular business conditions, and can demonstrate significantly increased capacity during major events like the Super Bowl for our gaming customers. Additionally, since we operate in the payments business, the risk evaluation must respond under strict time constraints. No customer will wait seconds to have their payment processed.
We’re leading the industry with our feature selection, regularisation, and parallel processing. We reduced up to 10x the response times and have all our new models with p99 latency below 200ms with some models actually responding below 35ms!
When we process tasks in parallel instead of in sequence, the total elapsed time is driven by the
Besides latency, we also introduced several safeguards and fallback strategies to protect us from several failure scenarios. If our models go down or are fed with corrupted data, it presents a major problem! To prevent this risk, we developed strong control measures and processes. Every change in models and policies follows strict governance procedures, like peer review, model cards, automated testing, test coverage checks, stress testing, and several other forms of validations. Additionally, we have safeguards in place to reduce the blast radius and severity of potential incidents. For example, every model is escorted by at least one fallback model that can be activated if the main one becomes unavailable. The fallback model can act as a substitute if a feature group fails to be calculated or the model endpoint starts to timeout, thus allowing us to continue operations without downtime in case of failures.
Imagine the scenario where a given data provider fails. All features dependent on the unavailable source will be affected. The absence of, or worse, the corruption of several features can hurt model performance if it is highly dependent on them. When we develop a model, we also produce alternative versions without specific feature groups. For example, if a data source fails and a specific set of features becomes unavailable or corrupted, we can redirect the traffic to the fallback model instead. This approach allows us to continue to operate in a more predictable setting.
Even if performance is degraded as the fallback model will always be worse than the main model, since we have validated the fallback model offline, we still have a good estimation about the performance loss. Otherwise, if we simply used the main model with the corrupted features, we can’t anticipate how it will behave. Of course, some failure scenarios can be anticipated and validated offline, but it can be difficult to anticipate failures, so we consider fallback strategies a more reliable approach. We also employ a fallback model as a last resource in case of severe infrastructure failure. If all model services become unavailable, start to timeout, or even a network issue prevents the main application server from calling our models, we still have a fallback model hardcoded in the main application server code.
MACHINE LEARNING PLATFORM: SCALE ACROSS THOUSANDS OF FINANCIAL INSTITUTIONS THROUGH STANDARDISATION
Financial institutions are diverse and, thus, some may be more reliable than others when it comes to data standards. One of the most difficult challenges to overcome in open banking is the difficulty of establishing a single data standard among all financial institutions. Every institution has its particular ways of managing and sharing its data. Trustly consolidates the financial data across financial institutions and categorises it in a single standard data model. Our unified data model allows us to build a Feature Store that centralises data from all the financial institutions connected to Trustly: the same sets of features can, therefore, be used for both major banks and local ones. This high level of standardisation allows us to scale our ML operation across institutions and geographies. We currently have more than 6000 features that can be reused among all our machine learning models to improve decision-making.

While features can be plugged into any model, we often need to give specific attention to key merchant partners or financial institutions. For example, a major financial institution in the US may require a specific model, while minor institutions with similar behaviour can be grouped in a single model. Trustly currently operates several individual machine learning models along with other models that challenge the ones in production to ensure a continuous feedback loop. We keep striving to improve our performance.
While in most industries data science teams often operate as craftsmen, where each model development has a dedicated data scientist and its own code, Trustly requires a more industrial approach. As part of our platform, we created a standardised model pipeline covering all aspects from model creation, deployment, and observability, including data preparation, feature selection, hyperparameter tuning, regularisation, features validation, orchestration, artefact tracking, and service endpoint wrapping. This pipeline is versioned in an internal library. It is config-driven and is based on configurable steps.
For example, it is mandatory to apply hyperparameter tuning for model development, but choosing different tuning algorithms through a declarative configuration is possible. Through this effort, we managed to reduce model development time from about three months to a single week. We were able to refresh all our models through automated retraining thanks to having this standardisation in place.
EXPERIMENTATION, FAST ITERATION AND THE FEEDBACK LOOP PROBLEM
The standard training pipeline allows us to keep iterating on our risk models with outstanding agility. It automates most of the development and deployment process to boost our data science team productivity. However, engineered processes and automation are great but ‘it is all about the data’. The data we have available to retrain models is what really moves the needle and can effectively allow us to evolve our models over time. Let’s recall the ‘non-sufficient funds’ (NSF) problem. As I mentioned earlier, the risk models are key in deciding to approve or decline a transaction. Note that we can only know if a given transaction effectively became a NSF if it was approved. If we decline a transaction, we can never know if it was a good or bad decision. Because the transaction never occurred, we would not know whether the transaction would become a financial loss or not. After I start using a model in production, it is expected that it will affect the data I get for next iterations as I will only know the outcome for transactions the model considers not risky, the ones effectively approved. Note that ‘the transactions the model considers a risk’ is different from ‘the transactions that will become an NSF’. Machine learning models are inherently approximations and imperfect, so part of the transactions it considers safe will become NSF (false negatives) and part of the transactions it considers risky won’t actually become NSF (false positives). In our setup where we only see the outcome for approved transactions, we are actually blind to the false positives. If we use this biased data to retrain a next iteration model and replace the previous one, the new model will likely only learn to discriminate among the false negatives of the previous model. If you launch it and replace the previous model, it will perform poorly as it will have to deal with the transactions that were previously declined and, thus, unseen to it. In the end, the new model will most likely learn the bias of the previous one instead of actually becoming better at the task at hand. We call this phenomenon a ‘degenerative feedback loop’, which is often found in problems like ours where the treatment, the decision of approving or declining a transaction, causes a selection bias in the data affecting the next model iterations.
While the stakes are high, the ability to access fresh consumer financial data gives us a competitive advantage to build data products at scale using machine learning. We’re the only open banking provider using this approach.

There are many ways to solve this feedback loop problem. The most simple one consists of approving a random sample of transactions without consulting the model. Of course, if we approve transactions that would be otherwise declined by the model, we can retrain and evaluate future iterations, avoiding the feedback loop. Note that the bigger this unbiased sample is, the more NSF you will get as you will approve risky transactions. The balance between letting more transactions in so that you can learn from them and build better models later versus using the current model to block as many risky transactions as possible is not trivial and known as the ‘exploration versus exploitation’ problem. At Trustly, we apply more sophisticated approaches that minimise the cost of exploration with causal inference techniques combined with experimentation designs. For example, instead of assigning the same probability of bypassing the model for every transaction, we could prioritise transactions with lower amounts or even capping high amount transactions to prevent losses. Of course, this will introduce a selection bias, but it can be later treated accordingly during training. Other approaches may include more sophisticated techniques like building synthetic balanced datasets by combining approved data from different models or experiment designs specific for this purpose.
Scaling Ai In Open Banking
We are a small and young machine learning engineering and data scientists team. There is still plenty of foundational work to do. It may not be today, tomorrow, or next year, but we are confident that our work will set the stage for world-class AI in open banking. Trustly has cracked the surface and dug so deep that it hit the big reservoir of the North American financial system that is open banking data coupled with machine learning. The data is pumping. It is time to continue building our machine learning platform to fuel new open banking applications.








