4 minute read
Launch your project with LeewayHertz

Incorporate a powerful recommendation system into your customer-facing app for enhanced user engagement
Learn More
Advertisement
How to build a recommendation system? A case study in Python using the MovieLens dataset
Numerous datasets have been gathered and made accessible for research and benchmarking purposes with respect to recommendation systems. Below is a list of topnotch data sources to consider. For beginners, the MovieLens dataset curated by GroupLens Research is highly recommended. Specifically, the MovieLens 100k dataset is a dependable benchmark dataset with 100,000 ratings from 943 users for 1682 movies. Moreover, each user has rated at least 20 movies. This extensive dataset comprises various files that furnish details on the movies, users, and ratings provided by users for the movies they have viewed.
The ones that are of interest are the following: u.item: the list of movies u.data: the list of ratings given by users
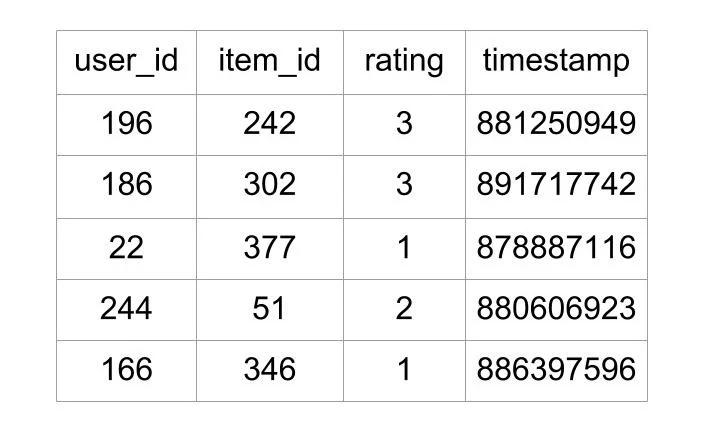
Contained within the file “u.data,” are ratings presented in a tab-separated list that includes user ID, item ID, rating, and timestamp. The initial lines of the file are as follows:
As demonstrated previously, the file discloses a user’s rating of a specific film. This file holds a total of 100,000 such ratings and will be utilized to anticipate the ratings of movies that users are yet to see.
Building a recommender using Python
Python offers numerous libraries and toolkits with diverse algorithm implementations for creating recommenders. However, when it comes to understanding recommendation systems, exploring Surprise is highly recommended. Surprise is a Python SciKit that offers a variety of recommender algorithms and similarity metrics. Its purpose is to simplify the process of constructing and analyzing recommenders.
Here’s how to install it using pip:
$ pip install numpy $ pip install scikit-surprise
Here’s how to install it using conda:
$ conda install -c conda-forge scikit-surprise
You also need to install Pandas
$ python3 -m pip install requests pandas matplotlib
Before utilizing Surprise, it’s crucial to familiarize yourself with a few fundamental modules and classes that it offers:
The Dataset module is utilized for loading data from files, Pandas dataframes, or even built-in datasets accessible for experimentation. The built-in MovieLens 100k dataset is one such dataset within Surprise. To load a dataset, various methods are available, including:
Dataset.load_builtin()
Dataset.load_from_file()
Dataset.load_from_df()
The Reader class is utilized for parsing files that contain ratings. Its default format accepts data where each rating is stored on a separate line, with the order being user, item and rating. These order and separator settings can be customized using the parameters:line_format is a string that stores the order of the data with field names separated by a space, as in “item user rating”.sep is used to specify separators between fields, such as ‘,’.rating_scale is used to specify the rating scale. The default is (1, 5).skip_lines is used to indicate the number of lines to skip at the beginning of the file. The default is 0.
Below is a program that can be used for loading data from either a Pandas data frame or the built-in MovieLens 100k dataset:
# load_data.py import pandas as pd from surprise import Dataset from surprise import Reader
# This is the same data that was plotted for similarity earlier # with one new user "E" who has rated only movie 1 ratings_dict = {
"item": [1, 2, 1, 2, 1, 2, 1, 2, 1],
"user": ['A', 'A', 'B', 'B', 'C', 'C', 'D', 'D', 'E'],
"rating": [1, 2, 2, 4, 2.5, 4, 4.5, 5, 3],
} df = pd.DataFrame(ratings_dict) reader = Reader(rating_scale=(1, 5))
# Loads Pandas dataframe data = Dataset.load_from_df(df[["user", "item", "rating"]], reader)
# Loads the builtin Movielens-100k data movielens = Dataset.load_builtin('ml-100k')
In the program above, the data is stored in a dictionary, which is loaded into a Pandas dataframe and then further into a Dataset object from Surprise.
Selecting the algorithm for the recommender system
To select the appropriate algorithm for the recommender function, it is necessary to consider the technique being used. In the case of memory-based approaches mentioned earlier, the KNNWithMeans algorithm, which is closely related to the centered cosine similarity formula discussed above, is an ideal choice.
The function must be configured to determine similarity by passing a dictionary containing the necessary keys as an argument to the recommender function. These keys include:
“name”: This key specifies the similarity metric to be utilized. Available options are cosine, msd, pearson, or pearson_baseline. The default is msd.
“user_based”: A boolean that indicates whether the approach will be user-based or item-based. It is set to True by default, meaning the user-based approach will be used.
“min_support”: This key specifies the minimum number of common items necessary between users to consider them for similarity. For the item-based approach, it corresponds to the minimum number of common users between two items.
The following program configures the KNNWithMeans function:
# recommender.py from surprise import KNNWithMeans
# To use item-based cosine similarity sim_options = {
"name": "cosine",
"user_based": False, # Compute similarities between items
} algo = KNNWithMeans(sim_options=sim_options)
The above program configures the recommender function to use cosine similarity and to find similar items using the item-based approach.
To use this recommender, you need to create a Trainset from the data. Trainset is built using the same data but contains more information, such as the number of users and items (n_users, n_items) used by the algorithm. You can create Trainset either by using the entire data or a subset of it. You can also split the data into folds, where some of the data will be used for training and some for testing.
Here’s an example to find out how the user E would rate the movie 2: from load_data import data from recommender import algo trainingSet = data.build_full_trainset() algo.fit(trainingSet)
Computing the cosine similarity matrix...
Done computing similarity matrix.
<surprise.prediction_algorithms.knns.KNNWithMeans object at 0x7f04fec56898>
